


Overview
Introduction to Quality Assurance: Why Functional Testing Matters
Functional testing is critical to quality assurance. Identifying and correcting errors pre-release helps ensure the reliability and stability of APIs and web services as well as build confidence among your key stakeholders.
Integration testing bridges the gap between unit testing and software testing, helping your team test potential side effects before they become big-time issues. Even if individual modules are successfully unit tested, errors may still exist after integration. By analyzing multiple parts of an application and aggregating the results, integration testing can help identify issues that may not have been obvious by testing specific units in isolation or that may have occurred during the interplay of several components of the application.
While unit tests are great for verifying that small units of code work as expected in isolation, integration tests verify that the interactions between multiple units of code produce the expected behaviors. A common example of this relationship is writing to a database. In a unit test, we can verify that the call to write to the database occurred at all or that an appropriate query was constructed, but the responses are mocked out. Integration testing allows us to confirm that an actual database will be happy with our request.
Integration Testing in Action: Testing DynamoDB with TestContainers
DynamoDB is a hosted NoSQL database offered by Amazon Web Services (AWS). The AWS SDK provides us access to the DynamoDBEnhancedAsyncClient, which allows us to manage the database from code. The client allows us to connect to our hosted database, construct table schemas, perform queries, and write data. The process is very similar to other Object-Relational Mapping (ORM) libraries that allow you to interact with a database from code.
While normally hosted on their servers, Amazon does provide a local version of DynamoDB so that when attempting to write integration tests, our database client doesn’t have to point to AWS servers when writing new code. According to Amazon’s documentation, this local version helps “save on throughput, data storage, and data transfer fees,” all without the need for an internet connection while the application is in development. Even better, this local version of DynamoDB is available as a Docker image. Running the database in a docker container saves us from having to manage installation and configuration of a local database across various development environments involved in the project.
Tapping into TestContainers: A Kotlin and Java Solution
A Java library that supports JUnit tests, TestContainers provide “lightweight, throwaway instances of common databases, Selenium web browsers, or anything else that can run in a Docker container.”
While docker saves us time from having to manually install and configure dynamoDB on every development machine, TestContainers saves us additional effort by letting us manage these docker containers from code. The plan, then, is to use TestContainers to pull and spin up a dynamoDB local image, point our dynamoDB SDK client to our local docker container instead of AWS, and pass this client into any services that take a dynamoDB client as a dependency.
The following examples of implementing TestContainers come from a back end API that is powered by the Ktor framework and uses Koin for dependency injection.
Project and Test Orchestration in Kotlin with Gradle
First, we need to add the Gradle dependency in build.gradle.kts.
Next, we initialize the container. We use a singleton object called our ContainerAccessor to hold various TestContainer instances. The TestContainer for our DynamoDb instance is stored in a variable of the same name.
In the above example, the DockerImageName points to the dynamodb/local docker image that Amazon hosts on their ECR. A fallback image is also provided, by name only (which attempts to grab the image from docker hub).
For our Integration Test setup we use an abstract class called BaseIntegrationTest. It is here that we need to actually start up the previously defined TestContainer.
We also create a seedDatabases protected function on the BaseIntegrationTest that can be called at the appropriate time. (This task is covered in greater detail in Seeding Strategy.
Implementing the abstract BaseIntegrationTest are BaseRouteIntegrationTest and BaseServiceIntegrationTest. Each handles setup a little bit differently since we’re concerned with testing at different layers of the application. In both classes, we initialize our Koin module which is responsible for dependency injection. It’s here that we set up our actual dynamo db client using the AWS SDK alongside any data services that might take the client as a dependency.
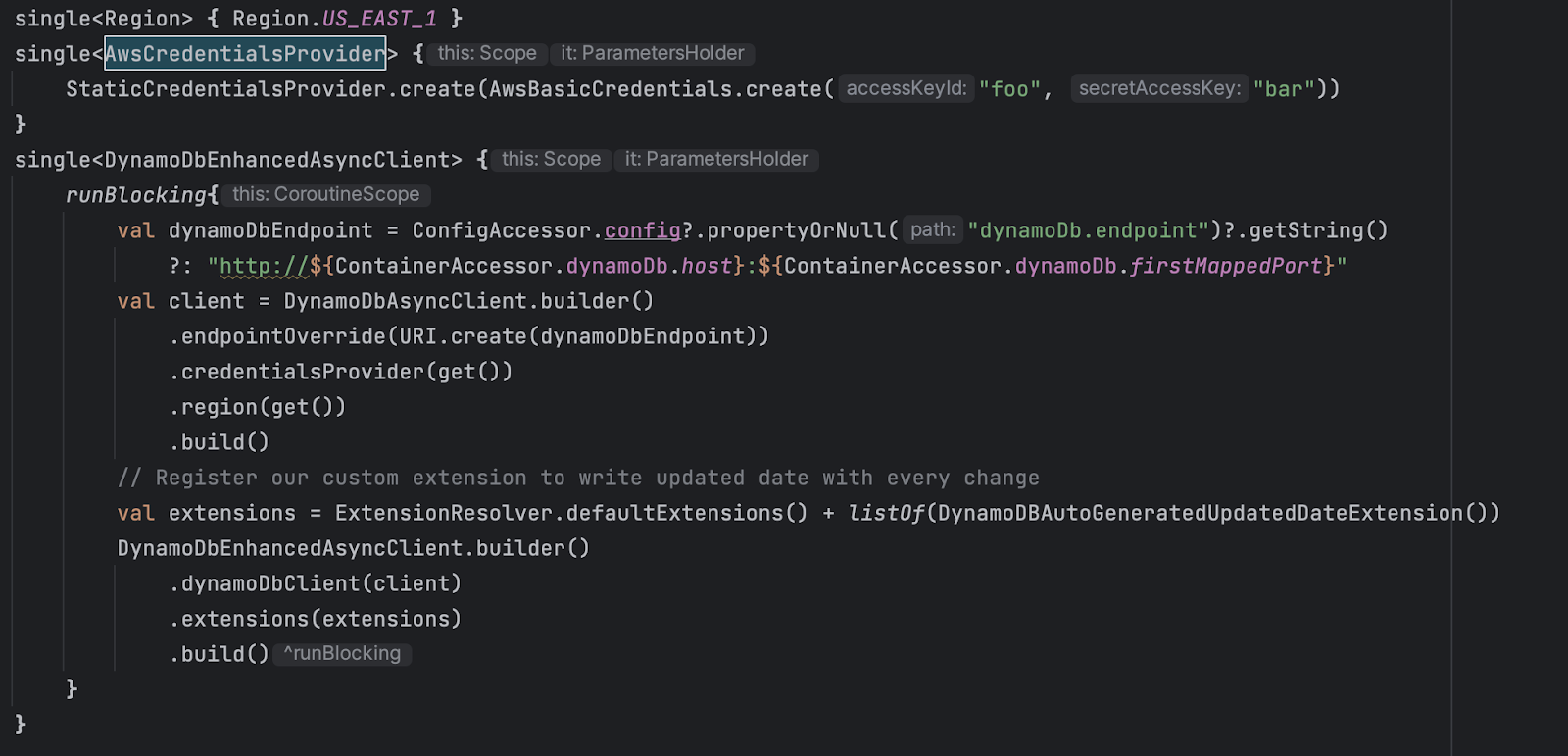
Now the Dynamodb enhanced async client points to our docker container, which is running DynamoDB and is managed by TestContainers.
Our database is still empty, however, and it’s also important to note that tables should be created and seeded before invoking any data service that takes the Dynamodb client as a dependency. Koin instantiates its singletons lazily, so we just need to seed our tables and data ahead of invoking any services that depend on our database.
Seeding Strategy: Implementing Data Setup in DynamoDB
As previously mentioned,
our abstract BaseIntegrationTest has a method for seeding our database, so in our BaseRouteIntegrationTest and BaseServiceIntegrationTest classes we call that method right after we’ve set up our Koin module.
We can begin to create tables from schemas, add those tables to the database, and seed data all using the SDK. While our project uses a few custom extension functions to aid in translating our model definitions into schemas and tables, for a DynamoDbBean annotated model, this process generally looks like the following:
Writing an Integration Test: A Guide
So far, our abstract BaseIntegrationTest has started our TestContainer, and our implementations of that class instantiate the SDK within our Koin module before calling our seed function.
Assuming you have a data service that is responsible for reading and writing to a given table, you can write tests at this point not entirely dissimilar from many unit tests you may have already written. The benefit this time around is that you’ll get actual responses from the database, such as when a record has a version mismatch. Chances are, some of the mock data you were using before isn’t actually up to par. For an API, the most bang for your buck is to write an integration test at the route level. Making the HTTP request should result in a call to some data service, which transacts with a database - returning some data that becomes part of the server response.
In the following example, the INTEGRATION_TEST_AMENITY_LIST_ITEM was previously seeded, and is the only Amenity seeded to our Amenities table matching the supplied property id of 1 in the route:
To recap:
- We make an HTTP request which hits the route specified.
- The route calls on the data service responsible for reading and writing data to this table.
- The data service makes a query against the database running in our docker container.
- The database returns the object, which is returned from the service, which is passed into the server response.
- We assert that the object in the server response was the expected value.
Pitfalls of TestContainers
One of the perks of using the TestContainers library is that after each test, the TestContainers library handles tearing down the container that was spun up for that particular test, by using a privileged container that orchestrates the entire affair. When the whole test suite is finished, the privileged container cleans itself up as well. By automatically starting and stopping docker containers in between each test. Each new container that is spun up for each test starts with the same initial state, which also makes it trivial to anticipate what data exists from one test to the next.
This is evident in an example from Docker Desktop, where each container that appears and disappears was created, used, and thrown away for an individual test:

This behavior was achieved by using the Rule annotation from JUnit 4, though different versions of TestContainers have different mechanisms by which this feature is enabled. While it was convenient to write each test without worrying about what data looked like at that particular moment in time (each test starts with the initial seed data only), build times were severely inflated. As the number of integration tests reached the hundreds, we found that we were able to shave 10-15 minutes off of our CodeBuild time by not using this feature.
Even without this feature, TestContainers continues to provide us with an easy way to run integration tests against a dockerized dynamoDB with virtually zero configuration — all you need is to have docker installed and running on your machine. We’ve even continued to use this approach in End-to-End testing! Using the same ContainerAccessor and Seeder that we use in integration testing, our E2E application spins up a DynamoDB TestContainer, initializes the DynamoDB SDK in its Koin module, seeds the database and exposes the API locally for a front end to interact with.
Making the Most of Your Integration Testing | Phase 2
For more than two decades, Phase 2 has been creating custom world-class automation and testing solutions for everything from well-funded startups to large-scale enterprises and beyond. Our proven processes leverage our deep experience and expertise in testing capabilities, while our bench of seasoned software developers and creatives work directly with clients to deliver the best possible outcomes.
Phase 2 is a trusted technology partner built on a deeply ingrained culture of collaboration and cooperation, and our commitment to excellence is an integral part of who we are. If you’re looking for a bespoke solution to optimize your next technology phase or for an opportunity to join a driven and dedicated team of top-tier talent, contact us or visit our Careers page.
.png)
.png)
